глоссарий
Поиск в руководстве по статистике Интернета
BD (недостающие данные). См. пропущенные значения ,
Нет сезонности, нет тенденции. Эта модель временной ряд , эквивалентно простой модели wyrwnywania wykadniczego , Обратите внимание, что по умолчанию первое значение будет рассчитываться на основе инициалов среднего значения S0 среднего ряда.
Без сезонности тенденция уменьшается. В этой модели временной ряд прогнозы простого выравнивания установщика «усиливаются» компонентом тренда пожаротушения (независимо уравниваются с помощью параметров 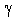 для тренда и
для тренда и 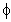 для эффекта пожаротушения). Например, мы хотели бы из месяца в месяц прогнозировать процент домохозяйств, имеющих конкретное электронное устройство (например, видеокамеры). Каждый год доля домохозяйств, имеющих камеры, растет, но эта тенденция будет преодолена (т. Е. Тенденция роста будет постепенно исчезать) с течением времени в результате насыщения рынка.
для эффекта пожаротушения). Например, мы хотели бы из месяца в месяц прогнозировать процент домохозяйств, имеющих конкретное электронное устройство (например, видеокамеры). Каждый год доля домохозяйств, имеющих камеры, растет, но эта тенденция будет преодолена (т. Е. Тенденция роста будет постепенно исчезать) с течением времени в результате насыщения рынка.
Чтобы рассчитать скорректированное значение (прогноз) для первого наблюдения ряда, необходимы оба уровня S0 и T0 (начальный тренд). По умолчанию эти значения рассчитываются как:
T0 = (1 / 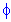 ) * (Х-Х1) / (N-1),
) * (Х-Х1) / (N-1),
где
N - количество наблюдений в серии, является параметром выравнивания тренда тушения,
и S0 = X1-T0 / 2.
Нет сезонности, линейный тренд (метод Холта, два параметра). В этой модели временной ряд предсказания простого эквалайзера эквалайзера «усиливаются» компонентом линейного тренда, который уравнивается независимо с параметром (гамма) (см. соображения по параметр выравнивания тренда ). Эта модель также называется методом Холта двух параметров . Например, эта модель может быть удобной при расчете прогнозов поставок запасных частей. Спрос на конкретные запасные части может замедляться или расти медленно (компонент тренда), и эта тенденция может меняться медленно, например, когда различные устройства устаревают или перестают использоваться, что изменит тенденцию спроса на запасные части для этих устройств. ,
Чтобы рассчитать значение (прогнозы) для первого наблюдения в серии, необходимы как S0, так и T0 (начальный тренд). По умолчанию эти значения рассчитываются как:
T0 = (Xn-X1) / (N-1),
где
N - длина серии,
и S0 = X1-T0 / 2
Без сезонности, тренд каденции. В этой модели временной ряд предсказания простого эквалайзера эквалайзера «усиливаются» определяющим компонентом тренда (выровненным с помощью параметра ). Например, я хотел бы предсказать общую ежемесячную стоимость ремонта производственного устройства. Стоимость этой mgba имеет примерную тенденцию, то есть из года в год стоимость ремонта может увеличиваться на определенный процент или коэффициент, что приводит к постепенному экспоненциальному увеличению стоимости затрат на ремонт.
Чтобы рассчитать значение (прогноз) для первого наблюдения ряда, необходимы как S0, так и T0 (начальный тренд). По умолчанию эти значения рассчитываются как:
T0 = (X2 / X1)
и
S0 = X1 / T01 / 2.
Анонимность (при анализе корреспонденции). Срок исполнения анализ корреспонденции он используется по аналогии с физическим понятием «момент инерции» или суммой массы Времена делятся на квадрат от оси вращения (например, Greenacre, 1984, стр. 35). Это описано здесь как полное Хи-квадрат Пирсона для двухсторонней таблицы отсчетов, деленной на сумму всех наблюдений в таблице.
Нет вида (альфа). Он будет основан на отказе от нулевой гипотезы, хотя на самом деле это правда.
Более подробную информацию по этой теме можно найти в главе Анализ мощности теста ,
Неудачная или подходящая классификация в тесте и тестовом образце. Мера того, насколько хорошо полученная модель воспроизводит значения данных в образце и тестовом образце.
Bd RMS, корневой элемент от Rd Mean Rectitude. Будет определяться путем сложения квадратов или отдельных четвертей, деления полученной суммы на числа полученных значений и определения квадратного корня из полученного частного. Bd RMS - это одно значение для описания или резюме. См. Нейронные сети ,
Не стандарт. Стандартная ошибка (этот термин был впервые использован Yule, 1897) - это стандартное отклонение для среднего распределения (или другой статистики) от попытки. Стандартная ошибка рассчитывается по формуле:
Bd стандарт = корень (s2 / n)
где:
s2 - отклонение от попытки
n означает много попыток.
Нет стандартного соотношения (фракция). Нестандартное соотношение - это стандартное отклонение для распределения пропорций (фракций) от образца. Если доля населения  а количество попыток N, то стандартная ошибка пропорций равна:
а количество попыток N, то стандартная ошибка пропорций равна:
sp = (p (1-p) / N) 1/2
Более подробную информацию можно найти в главе Анализ мощности теста ,
Будь стандартным медиумом. Будучи стандартной ошибкой , этот термин впервые был использован Yule, 1897) - это стандартное отклонение для среднего распределения из выборки числа n, выбранного из популяции. Стандарт по умолчанию будет зависеть от дисперсии в популяции (сигма) и количества выборок ( n ) по формуле:
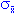 = (
= (  2 / п) 1/2
2 / п) 1/2
где: 2 является дисперсия в популяции
n - количество попыток.
Поскольку дисперсия в популяции обычно не известна, наилучшая оценка стандартной ошибки:
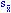 = (s2 / n) 1/2
= (s2 / n) 1/2
где
s2 это дисперсия из попытки (оценка дисперсии мы выбрали)
n - количество попыток.
Смотрите также Описательная статистика - Введение ,
Нет совпадений. Для некоторых систем, содержащих вентиляцию в пределах уровня предикторов, остаточную сумму квадратов можно разделить на компоненты, относящиеся к проверенным гипотезам. Остаточные суммы квадратов можно разделить на несовпадающий компонент и чистую ошибку. Это требует определения определенной части остаточной суммы квадратов, которая может быть предсказана путем введения в модель дополнительных переменных для предиктора качества (например, полиномиальных выражений или взаимодействий) и части суммы квадратов, которая не может быть предсказана никакими дополнительными источниками (т.е. квадраты для чистой ошибки). Затем вы можете выполнить тест несоответствия, используя либо описание, либо средний квадрат для чистой ошибки. Благодаря этому мы получаем более чувствительный тест соответствия модели, потому что выражение, описывающее или исключающее влияние дополнительных выражений более высокого порядка, будет удалено.
Больше информации также можно найти под лозунгами чистый бд , матрица эксперимента и в разделах Общие линейные модели (GLM) , Общие регрессионные модели (ГРМ) или Экспериментальное планирование ,
Недостающие ценности. Это неизвестные значения переменных в наборах данных. Хотя случаи, содержащие пропущенные данные, являются неполными, их можно использовать при анализе данных. Существуют разные способы замены отсутствующих данных (например, замена среднего разные типы интерполяция и экстраполяция ). Это также может быть использовано удаление недостающих данных попарно и удаление недостающих данных по делам ). Список преимуществ и недостатков различных способов борьбы с отсутствующими данными находится в разделе Удаление отсутствующих данных в парах и замена среднего и Удаление недостающих данных по случаям или парам в главе Основная статистика ,

& copy Copyright StatSoft, Inc., 1984-2011
STATISTICA является торговой маркой StatSoft, Inc.