Усиленные деревья классификации и регрессии
& copy Copyright StatSoft, Inc., 1984-2011
Поиск в руководстве по статистике Интернета
Укрепленные деревья классификации и регрессии Укрепленные деревья классификации и регрессии - Введение в стохастическое усиление градиентаОбщий вычислительный подход усиленных деревьев известен под названиями TreeNet (™ Salford Systems, Inc.) и MART (™ Jerill, Inc.). За последние несколько лет эта техника стала одним из самых мощных методов интеллектуальный анализ данных , Реализации этих алгоритмов позволяют использовать их в задачах регрессии и классификации, для количественных и качественных предикторов. Подробное описание этих методов с технической стороны можно найти в Friedman (1999a, b) и в Hastie, Tibshirani and Friedman (2001).
Укрепление градиентных деревьев
Алгоритм укрепленных деревьев развивается на основе применения методов укрепление для деревьев регрессии [ср. также Общая классификация и деревья регрессии (GC & RT) ]. Идея Gwn состоит в том, чтобы создать серию (очень) простых деревьев, каждое из которых построено, чтобы предсказать остальное, сгенерированное предыдущими. Как описано в Введение в общую классификацию и деревья регрессии метод строит двоичные деревья, то есть делит данные на две выборки в каждой строке деления. Слухи о том, что мы ограничили количество деревьев до 3 кур (на самом деле, пользователь может определить, что должно быть zoono): то есть дерево состоит из корня и двух потомков, то есть только одного деления. На последующих этапах усиления (алгоритм амплификации дерева) определяется одно (наилучшее) разделение данных и вычисляются отклонения наблюдаемых значений от средних значений (остатки в каждом делении). Следующее дерево с тремя wzes сопоставляется с этими остатками и отмечает следующее деление, которое сопоставляется с этими остатками и отмечает следующее деление, при котором дисперсия остатков (то есть bd) еще меньше (для данного диапазона деревьев).
Можно доказать, что такая процедура «аддитивного развертывания взвешенных» деревьев приведет к идеальному соответствию прогнозируемых значений с наблюдаемыми значениями, даже если характер отношений между предикторами и переменной зависимости очень высок (например, нелинейный). Таким образом, метод улучшения градиента - настройка взвешенной аддитивной разработки простых деревьев - является очень общим и мощным алгоритмом. машинное обучение ,
Проблема перетекания в стохастическом градиентном усилении
Одной из основных проблем во всех алгоритмах машинного обучения является решение «когда оно остановится» и, таким образом, как предотвратить чрезмерное соответствие алгоритма обучения нетипичным аспектам конкретного обучающего набора, что не улучшает предсказательную силу созданной модели. Эта проблема известна под именем чрезмерная корректировка , Это общая проблема, которая затрагивает большинство алгоритмов обучения, используемых в интеллектуальный анализ данных ,
Общее решение этой проблемы, используемое, например, в методах MARSplines и в SNN он основан на расчете качества модели на основе тестового образца, созданного на основе данных, которые ранее не «использовались» для оценки модели. Таким образом, мы надеемся оценить точность прогнозируемого решения и определить, в какой момент начинается чрезмерная корректировка.
Подобный подход используется в укрепленных деревьях. Каждое последующее дерево сначала строится на основе случайной подпрограммы из всего набора данных. Другими словами, последующие деревья создаются для прогнозирования остатков (из всех предыдущих) в случайно выбранных файлах. Введение определенной степени случайности для анализа может быть использовано в качестве гарантии от переоснащения (поскольку каждое дерево построено для других наблюдений) и дает модели (аддитивное взвешенное развитие простых деревьев), которые обобщаются и хорошо предсказывают новые наблюдения, то есть имеют хорошую точность прогнозирования. , Этот метод (т. Е. Вычисление для случайно выбранных случайных выборок) называется стохастическим градиентным усилением .
На приведенном ниже графике представлен график функции прогнозирования для обучающих данных и для тестовых образцов, отобранных независимо на каждом этапе.
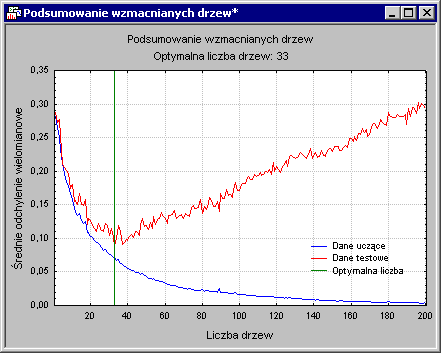
На этом графике вы можете быстро указать точку, в которой модель (состоящая из определенного числа деревьев, созданных на последующих этапах) начинает показывать чрезмерное соответствие данным.
Можно заметить, что прогноз в выборке будет постепенно уменьшаться по мере добавления компонентов в модель. Тем не менее, в области 33 деревьев модель для независимо взятого тестового теста начинает вести себя все хуже и хуже. Это означает, что в этот момент модель начинает демонстрировать чрезмерное соответствие данным.Стохастическое градиентное усиление и классификация
До тех пор усиленные деревья обсуждались только для применения к задачам регрессии, то есть прогнозу количества зависимой переменной. Этот метод может быть легко распространен на задачи классификации (описание см. Friedman, 1999a, глава 4.6, в частности алгоритм 6):
Во-первых, различные усиленные деревья строятся для каждой категории или класса качества зависимой переменной (сопоставляются с ней) после создания переменных (векторов) с кодами 0 и 1, которые указывают, принадлежит ли наблюдение к классу или нет. На следующих этапах усиления алгоритм выполняет логистическая трансформация (См. Нелинейная оценка ) рассчитать остальное. При вычислении вероятностей окончательной классификации логистическое преобразование снова применяется к вектору прогнозирования со значениями, закодированными 0/1. Алгоритм подробно описан в Friedman (1999a, см. Также Hastie, Tibshirani and Freedman, 2001, для подробного описания этой общей процедуры).
Большое количество классов Стоит отметить, что такая процедура для задач классификации требует построения отдельных последовательностей (усиленных) деревьев для каждого класса. Вычислительный Zoono умирает, когда растет количество необходимых решений линейной регрессии (для одного количественного класса зависимой переменной). Поэтому анализировать качественные переменные, имеющие более 100 классов, нецелесообразно, поэтому для этого числа вычислений могут потребоваться очень большие «прогоны» и время. Например, в задаче с 200 шагами усиления и 100 категориями или классами зависимых переменных это дает 200 * 100 = 20000 отдельных деревьев!
& copy Copyright StatSoft, Inc., 1984-2011
STATISTICA является торговой маркой StatSoft, Inc.
Похожие
5 способов использовать искусственные деревья - Блог TwojaPasaż.pl5 способов использовать искусственные деревья Каждый из нас любит окружать себя красивыми вещами, независимо от того, где мы находимся в данный момент. Именно по этой причине цветы в горшках появляются почти в каждом доме,