Фокус анализ
& copy Copyright StatSoft, Inc., 1984-2011
Поиск в руководстве по статистике Интернета
Фокус анализОбщая цель
Концепция кластерного анализа, термин, введенный в работе Триона в 1939 году, на самом деле охватывает несколько различных алгоритмы классификация. Общая проблема исследователей во многих дисциплинах состоит в том, чтобы организовать наблюдаемые данные в разумные структуры или группировки данных. Другими словами, анализ закупок - это инструмент для исследовательского анализа данных, цель которого состоит в том, чтобы поместить объекты в группы таким образом, чтобы отношения объекта с объектами, принадлежащими к одной и той же группе, были как можно большими, а объекты из других групп - как можно меньшими. Анализ фокуса может использоваться, чтобы обнаружить структуры в данных, не получая интерпретации / объяснения. Или, кратко: анализ фокуса только обнаруживает структуры в данных, не объясняя, почему они происходят.
Мы встречаемся с классификацией практически на каждом этапе повседневной жизни. Например, гости, проживающие за одним столом в ресторане, могут рассматриваться как группа людей. В продовольственных магазинах продукты подобного типа, такие как различные виды мисок или овощей, выставляются в одном месте или очень близко друг к другу. Есть много примеров, в которых кластер / классификация играет роль. Например, биологи, прежде чем они смогут разумно описать различия между животными, должны классифицировать их по видам. Согласно современной системе, используемой в биологии, люди принадлежат к приматам, млекопитающим, амниотам, крисквам и животным. С этой классификацией отметим, что чем выше уровень агрегации, тем меньше сходство между членами отдельных классов. Человек больше похож на всех других приматов (например, карты), чем на более «отдаленных» млекопитающих (например, psw) и т. Д. Обзор общих типов методов анализа будет сосредоточен на следующих трех темах: агломерация , Группировка объектов и объектов (группировка блоков) и Группировка методов k-среды ,
Проверка статистической значимости
Мы заметим, что в приведенном выше разделе мы опускаем алгоритмы группировки, и мы ничего не упомянули о проверке статистической значимости. Анализ покупок - это не статистический тест, а совокупность других алгоритмы что "группировать объекты в кластеры". Дело в том, что, в отличие от многих других статистических процедур, методы анализа будут сосредоточены на применении, когда у нас нет никаких априорных гипотез, но мы все еще находимся на этапе исследования нашего исследования. Следовательно, тестирование статистической значимости в традиционном смысле этого понятия на самом деле здесь не применимо, даже в случаях, когда заданы уровни p (как в методах группировки). к- средний ).
Области применения
Методы группировки используются во многих различных областях исследований. Отличный список многих опубликованных исследований, в которых сообщается о результатах анализа закупок, представлен Хартиганом (1975). Например, в области медицины группирование заболеваний, методов лечения или симптомов заболеваний может привести ко многим полезным классификациям. В психиатрии для успешной терапии необходим правильный диагноз симптомов, таких как паранойя, шизофрения и т. Д. В археологии исследователи, использующие методы анализа, покупают, используют инструменты для групповых камней, похоронные принадлежности и т. Д. В целом, когда нам нужно классифицировать «большой» источник информации в значимые группы, анализ будет сосредоточен на том, чтобы стать ценным инструментом.
агломерация
введениеПримеры, представленные в части Общие цели проиллюстрировать назначение алгоритма агломерации. алгоритм это подходит для группировки объектов (например, животных) в более крупные наборы (совокупности), используя определенную меру сходства или расстояния. Типичным результатом такого типа группировки является иерархическое дерево.
Иерархическое дерево
Мы разработаем уровни иерархической древовидной диаграммы, начиная с левой стороны диаграммы, где каждый объект является своим собственным классом. Теперь представьте, что мы «урезаем» наши очень маленькие шаги в той степени, в которой они являются или не являются уникальными. Другими словами, мы понижаем позицию решения о назначении двух или более объектов одному и тому же фокусу.
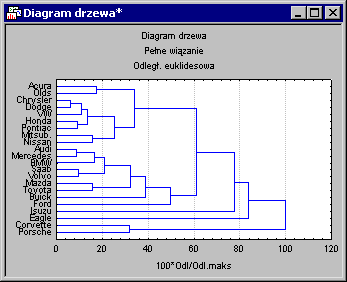
Таким образом, мы узнаем все больше и больше объектов и объединяем их во все большее и большее количество элементов, которые все больше и больше отличаются друг от друга. В конце концов, на последнем этапе все объекты связаны друг с другом. На этих диаграммах расстояния агломерации расположены на горизонтальной оси (на вертикальных участках сопел расстояние агломерации вычитается на вертикальной оси). Таким образом, с каждой дырой в графике (где был сформирован новый фокус) мы можем прочитать расстояние, на котором соответствующие элементы были связаны друг с другом, создавая новый отдельный фокус. Если данные имеют отличительные «структуры» в том смысле, что существуют кластеры объектов, похожих друг на друга, то часто эта структура будет отражаться в иерархическом дереве в виде отдельных сеток. Успешный анализ с помощью метода связывания дает возможность обнаружить покупки (gazi) и их интерпретацию.
Меры расстояния
В методе агломерации при измерении покупки используется разделение или расстояние между объектами. Например, если бы у нас было меню групповой панели, мы могли бы учитывать количество калорий, цены, субъективные вкусовые оценки и т. Д. Самый прямой способ вычисления расстояния между объектами в многомерном пространстве - это вычисление евклидова расстояния. Если у нас есть двух- или трехмерное пространство, эта мера определяет геометрическое расстояние между объектами в пространстве (т. Е. Полученное с помощью линейки). С точки зрения алгоритма, однако, безразлично, являются ли расстояния, которые мы «даем», реальными расстояниями или какими-то другими производными показателями расстояния, которые имеют большее значение для исследователя; следовательно, только исследователь выбирает правильную меру.
Евклидово расстояние. Это, вероятно, самый используемый тип расстояния. Так что просто геометрическое расстояние в многомерном пространстве. Он рассчитывается следующим образом:
расстояние (х, у) = {  и (xi - yi) 2} ½
и (xi - yi) 2} ½
Отметим, что евклидовы расстояния (и квадраты евклидовых расстояний) рассчитываются на основе необработанных данных, а не на основе стандартизированных данных. Этот метод имеет некоторые преимущества (например, расстояние между любыми двумя объектами не влияет на добавление новых объектов в анализ, которые могут быть выбросами). Однако на расстоянии влияние единиц измерения зависит от того, какие расстояния рассчитаны. Например, если одно из измерений означает длинное, измеренное в сантиметрах, то после преобразования его в миллиметры (относительные значения эквивалентны 10), чаще всего мы получим отчетливо разные евклидовы расстояния и квадраты евклидовых расстояний (рассчитанные для многих измерений). Это может привести к покупке других результатов покупки. В общем случае целесообразно применять стандартизацию, чтобы были доступны данные в сопоставимом масштабе.
Площадь Евклидова расстояния. Расстояние Евклидова увеличивается до квадрата, чтобы придать больший вес объектам, которые находятся дальше. Он рассчитывается следующим образом (см. Также комментарии выше):
расстояние (х, у) = и (xi - yi) 2
Расстояние до города (Манхэттен, городской квартал) . Это расстояние является просто суммой разностей, измеренных по размерам. В большинстве случаев эта мера расстояния дает результаты, аналогичные успешному евклидову расстоянию. Отметим, однако, что в случае этой меры влияние отдельных больших различий (выбросов) отбрасывается (потому что оно не возводится в квадрат). Дальний город рассчитывается следующим образом:
расстояние (х, у) = и | XI - YI |
Из Чебышева . Такая мера расстояния подходит в тех случаях, когда мы хотим определить два объекта как «разные», если они различны в каком-либо одном измерении. Расстояние от Чебышева рассчитывается следующим образом:
расстояние (x, y) = максимум | xi - yi |
Odgego Powgowa. Иногда мы хотим увеличить или уменьшить увеличение веса, которое присваивается измерениям, в которых соответствующие объекты сильно различаются. Это может быть достигнуто с помощью дистанции пота . Это считается следующим:
расстояние (х, у) = ( и | xi - yi | p) 1 / y
где r и p - параметры, определенные пользователем. Несколько образцов лиц могут показать, как ведет себя эта «мера». Параметр p контролирует увеличивающийся вес, который присваивается разнице в отдельных измерениях, параметр r контролирует растущий вес, который присваивается большему различию между объектами. Если r и p равны 2, то расстояние равно евклидову расстоянию.
Несоответствие в процентах . Эта мера особенно полезна, когда данные для измерений охватываются анализом и дискретной природой. Расстояние считается следующим:
расстояние (x, y) = (число xi  yi) / я
yi) / я
Методы подключения или визы
На первом этапе, когда каждый объект представляет свой собственный фокус, расстояния между этими объектами определяются с использованием выбранной меры расстояния. Как, однако, будет определять расстояния между новыми кластерами, которые возникают из связанных объектов? Другими словами, нам нужны визовые или агломерационные правила, которые будут определять, когда два кластера достаточно похожи, чтобы их можно было создать. Есть несколько вариантов: например, мы могли бы объединить два кластера, когда любые два объекта из этих двух покупок расположены на меньшем расстоянии, чем соответствующая дальняя виза. Другими словами, для определения расстояний между кластерами мы будем использовать ближайших соседей между кластерами; этот метод называется одиночной связью. В результате использования этого метода образуются «подмигивающие» кластеры, что означает, что они связаны друг с другом только отдельными объектами, которые находятся ближе всего друг к другу. В качестве альтернативы мы можем использовать соседей, которые наиболее удалены друг от друга; этот метод называется полной связью. Есть много других визовых правил, похожих на предложенные здесь.
Однократная виза (ближайший район) . Как было описано выше, в этом методе расстояние между двумя кластерами определяется расстоянием между двумя ближайшими объектами (ближайшими соседями), накапливающимися в разных покупках. Согласно правилам, объекты формируют группы поклонения в последовательностях, и получающиеся группы формируют длинные "группы".
Метод полного визажа (дальняя окрестность) . В этом способе расстояние между кластерами определяется наибольшим из расстояний между любыми двумя объектами для разных покупок (то есть, «наиболее удаленными соседями»). Этот метод обычно сдает экзамены в тех случаях, когда объекты на самом деле образуют естественно разделенные "кпки". Этот метод не подходит, если он ориентирован на способ его извлечения или характер «цепи».
Средний метод контакта В этом методе расстояние между двумя кластерами рассчитывается как среднее расстояние между всеми парами объектов для двух разных покупок. Этот метод эффективен, когда объекты образуют естественно отделенные «кпки», но также сдает экзамен в случае покупки потраченного типа «проститутка». Укажем, что Снит и Сокал в своей работе (1973) представили UPGMA (невзвешенный метод парных групп, использующий средние арифметические значения) для этого метода.
Средний Связанный Метод. Это метод, идентичный среднему , за исключением того, что в расчетах учитывается большая соответствующая покупка (т.е. количество объектов, содержащихся в них) в качестве весов. Следовательно, этот метод, а не предыдущий, следует использовать, когда мы подозреваем, что покупка будет отсутствовать. Sneath и Sokal (1973) представили метод WPGMA (метод взвешенных парных групп, использующий средние арифметические значения ) для этого метода.
Метод мер . Центр фокуса - это средняя точка в многомерном пространстве, определяемая этими измерениями. В этом методе расстояние между двумя кластерами определяется как разница между центрами тяжести . Sneath и Sokal (1973) используют UPGMC ( невзвешенный метод парных групп с использованием среднего по центроиду ) для обозначения этого метода.
Метод взвешенной гравитации (медиана). Это метод, идентичный предыдущему, за исключением того, что в расчетах вводится взвешивание для учета различий между количествами закупок (т. Е. Количеством объектов, содержащихся в них). Таким образом, этот метод лучше, чем предыдущий, когда есть (или мы подозреваем, что есть) существенные различия в размерах покупки. Sneath и Sokal (1973) используют WPGMC ( метод взвешенных парных групп, использующий среднее по центроиду ) для обозначения этого метода.
Метод Уорда. Этот метод отличается от всех других тем, что использует анализ дисперсионных подходов для оценки расстояния между кластерами. Короче говоря, этот метод направлен на минимизацию суммы квадратов отклонений любых двух покупок, которые могут быть сформированы на любом этапе. Подробности об этом методе можно найти в: Ward (1963). В целом, этот метод считается очень эффективным, хотя он нацелен на создание мелких покупок.
Обзор двух других методов группировки можно найти в темах: Группировка объектов и особенности и методы группировки к- средний ,
Группировка объектов и функций
введениеРанее мы обсуждали эти методы в терминах «объектов», которые должны быть сгруппированы (см. Агломерация - Введение ). Во всех других видах анализа вопрос исследования обычно выражается в виде случаев (наблюдений) или переменных. Оказывается, группировка случаев и переменных может привести к интересным результатам. Например, мы можем представить эксперимент, в котором исследователь будет собирать данные о различных показателях физической подготовленности (переменной) для исследования пациентов с сердечными заболеваниями (случаями). Исследователь может захотеть классифицировать случаи (пациентов) для выявления кластеров пациентов с подобными синдромами. В то же время исследователь может захотеть классифицировать переменные (показатели эффективности), чтобы обнаружить кластеры показателей, которые относятся к аналогичным физическим способностям.
Группировка объектов и функций.
После обсуждения в предыдущем абзаце относительно групповых случаев или переменных, почему бы не спросить обе группы одновременно? Анализ покупки включает в себя процедуры группировки объектов и признаков, которые им подходят. Группировка объектов и функций полезна в (относительно редких) обстоятельствах, когда мы ожидаем, что и случаи, и переменные одновременно способствуют обнаружению разумных систем закупок.
Например, возвращаясь к тому же примеру, исследователь может захотеть определить фокус пациентов, которые похожи из-за разной совокупности сходных показателей физической подготовленности. Такие результаты трудно интерпретировать, так как сходства между различными кластерами могут относиться (или проистекают из) к немного различным подмножествам переменных. Поэтому результирующая структура (заказ на поставку) не является однородной по своей природе. С самого начала это может показаться неясным и фактически по сравнению с другими описанными методами группировки (см. агломерация и методы группировки к- средний ), группировка объектов и объектов, вероятно, наименее используемая. Некоторые исследователи, однако, считают, что этот метод является мощным инструментом для исследовательского анализа данных (подробное описание этого метода можно найти в Hartigan, 1975).
Группировка k- средних методов Введение
Этот метод группировки значительно отличается от методов агломерация и Группировка объектов , Обратите внимание, что мы уже сформулировали гипотезу о количестве покупок наших дел или переменных. Мы можем «сказать» компьютеру сформировать ровно три агрегата, которые настолько различны, насколько это возможно. Он отвечает на этот тип проблемы исследования алгоритм группировка методов k-среды. Как правило, кластер будет создаваться с использованием метода K- типа, насколько это возможно. Следует отметить, что оптимальный номер покупки не известен из игры и должен рассчитываться на основе данных (см. Найти лучший номер покупки ).
Пример.
В примере по физической подготовке (см. Группировка объектов ), исследователь может «догадаться» (основываясь на клиническом опыте), что пациенты с сердечными заболеваниями будут классифицированы на три разные категории в зависимости от физической подготовленности. Может быть интересно посмотреть, можно ли количественно сформулировать эту интуицию, т. Е. Будет ли, согласно ожиданиям, анализ сосредоточен на методах средних значений физической подготовленности, которые фактически создадут три концентрации пациентов. Если это так, то среднее значение различных показателей физической подготовленности для каждого кластера будет представлять количественный способ выражения гипотезы или интуиции исследователя (т.е. пациенты, находящиеся в фокусе 1, высоко в мере 1, низко в мере 2 и т. Д.).
Расчеты.
С точки зрения лица, вы можете рассматривать эти методы как «обратный» анализ отклонений ( ANOVA ). Начинайте кадрирование случайным образом, затем перемещайте объекты между этими кластерами, чтобы (1) минимизировать вариацию внутри цели и (2) максимизировать вариацию между кластерами. Другими словами, максимальное сходство будет характеризовать членов данного кластера / группы, а минимальное сходство будет между членами данной группы и другими объектами. Это «обратный» дисперсионный анализ в этом смысле, и критерий значимости ANOVA компенсирует изменчивость межгрупп с внутригрупповой изменчивостью при проведении теста значимости для гипотезы о том, что среднее по группам не отличается друг от друга. В группировании методов k- medium мы пытаемся передавать объекты (например, случаи) между группами, чтобы получить наивысший уровень значимости анализа ANOVA.
Интерпретация результатов.
Обычно, в результате группового анализа k- средних методов , мы изучаем среднее значение для каждого кластера в каждом измерении, чтобы оценить, насколько наши кластеры отличаются друг от друга. В идеальной ситуации мы получили очень разные средние значения для большинства, если не для всех измерений, включенных в анализ. Большая F- статистика, полученная из анализа дисперсии, выполненной в каждом измерении, является показателем того, насколько хорошо данное измерение различает концентрацию.
Группировка электромагнитных методов Введение
Методы, используемые в случае изолированного анализа, аналогичны методу K- средних, используемому в стандартном анализе закупок, поэтому стоит ознакомиться с введением в группировку косвенных методов. Основная цель этих методов заключается в обнаружении наблюдений (или переменных) и распределении наблюдений для покупки. Типичным примером такого анализа является маркетинговое исследование, в котором для большой выборки респондентов собирается ряд переменных, описывающих поведение потребителей. Целью исследования является создание «сегментации рынка», то есть для обозначения групп респондентов, которые похожи друг на друга (то есть сходны в рамках одной и той же направленности) в отличие от потребителей из других групп. Помимо обозначения, покупка обычно также интересна, интересно определить, где различия отличаются друг от друга, то есть определить переменные и измерения, которые определяют фокус и определить, каким образом.
Группировка k- средних методов. Классический алгоритм k- middle был популяризирован Хартиганом (1975, см. Хартиган и Вонг, 1978). Основа алгоритма относительно проста: с фиксированным числом (заданным или предполагаемым) k мы фокусируем наблюдения, которые мы назначаем для покупки, чтобы среднее значение в кластерах (для всех переменных) было наиболее отличным друг от друга.
Расширения и потливость. Методы, использованные в рассматриваемом анализе с помощью методов EM и k-medium, являются продолжением этого подхода в трех важных аспектах:
- Вместо того, чтобы назначать покупки (наблюдения) таким образом, чтобы различия между средними (количественными переменными) в группах были как можно большими, алгоритм EM (максимизация ожидаемого значения) вычисляет вероятность принадлежности к покупке с учетом одного или нескольких распределений вероятности. Цель алгоритма - максимизировать общую вероятность (достоверность данных) для данного разделения на кластеры.
- В отличие от классической усредненной реализации, EM- алгоритм может использоваться как для количественных, так и для качественных переменных (мы обеспокоены тем, что классический промежуточный алгоритм также можно модифицировать, чтобы mg применялся к качественным переменным).
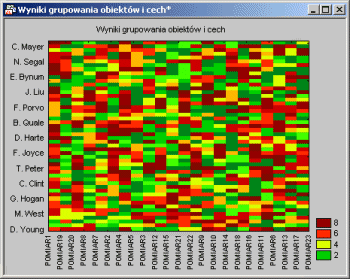
Алгоритм анализа покупки EM- методов подробно описан в Witten and Frank (2001). Основная идея этого метода: подумайте, что мы наблюдаем большую выборку одной количественной переменной. Кроме того, я предполагаю, что он состоит из двух групп наблюдений с различным средним (и, возможно, разными отклонениями). В каждом примере распределение значения переменной является нормальным. Результирующее распределение значений переменных может выглядеть следующим образом:
Смеси rozkadw. На рисунке выше показаны два нормальных распределения с разными средними и стандартными отклонениями, а также сумма этих двух распределений. Мы наблюдаем только смеси (суммы) этих двух распределений (с различными средними и стандартными отклонениями). Цель метода EM состоит в том, чтобы оценить средние и стандартные отклонения для каждой группы, чтобы максимизировать достоверность наблюдаемых данных (распределение). Другими словами, алгоритм метода EM пытается аппроксимировать наблюдаемое распределение распределений в виде смесей распределений разных групп.
Благодаря EM- методу, реализованному в компьютерной программе, мы можем выбирать (для непрерывных переменных) различные распределения, такие как распределение нормальный , логнормальное или Пуассон , Мы также можем выбрать различные декомпозиции для разных переменных и стандартных параметров, назначить группы из смесей разных типов распределения.
Качественные переменные. Реализация алгоритма EM может использовать переменные качества. Во-первых, он случайным образом назначает вероятности (веса) для каждого из классов (категорий) в каждой из покупок. На последующих итерациях вероятности корректируются для максимизации надежности данных при заданном объеме закупок.
Классификационные вероятности вместо классификации. Результаты анализа будут сфокусированы на методах ЭМ, отличных от тех, которые рассчитаны методами k- средних. Последний определяет концентрацию. Алгоритм EM не определяет назначение наблюдений классам, а вероятности классификации. В противном случае каждое наблюдение принадлежит каждому из них с определенной вероятностью .
В поисках лучшего номера будут куплены испущенные методы EM и k-medium: перекрестная проверка v-fold
Важный вопрос, который следует задать, чтобы начать анализ методов группирования EM и k-group, касается количества покупок. Это число не известно "априори"; мы не можем найти однозначного ответа на этот вопрос, то есть как мы должны использовать k . Фактически, k является параметром модели, который может привести к удару. Его значение можно получить из доступных данных с помощью метода перекрестной проверки. Методы создания закупок с использованием методов EM и k- and-medium оптимизированы и разработаны для типичных приложений для интеллектуального анализа данных. Общая концепция интеллектуального анализа данных предполагает, что аналитик ищет структуры и «слиток» в данных без каких-либо конкретных предварительных условий относительно того, что mgs найти (в отличие от гипотезы, типичной для научных исследований). На практике аналитик обычно не имеет представления о том, сколько стоит покупка в выборке. По этой причине некоторые программы включают реализацию v-кратный тест krzyowego - алгоритм, который автоматически определяет количество покупок данных.
Этот уникальный алгоритм широко используется для всех типов задач «поиска по шаблону». Количество сегментов рынка в маркетинговых исследованиях, количество различных маршрутов покупки в анализе будет удерживать клиентов, количество покупок различных медицинских симптомов, количество различных типов документов при добыче текста, количество погодных явлений в метеорологии, количество кремниевых чешуек и т. Д.
Алгоритм перекрестной проверки можно использовать в анализе покупки. Алгоритм v-перекрестной проверки подробно описан в контексте Деревья классификации , Общая классификация и деревья регрессии (GC & RT) , Идея этого метода состоит в том, чтобы разделить всю выборку на v подмножеств или нарисовать (расходящиеся) подмножества. Тот же анализ выполняется последовательно для наблюдения с подмножествами v-1 (выборка участника), и результаты анализа применяются к данным из выборки v (которые не использовались для оценки параметров, построения дерева, определения покупки и т. Д. И полной роли попытки теста ) и какая мера силы прогнозирования определяется. Результаты в воздухе агрегируются (усредняются) и дают оценку устойчивости модели, то есть ее способности прогнозировать новые наблюдения.
Фокус анализ является методом учить без учителя - концентрация - теоретическое творение. Разумным является заменить понятие «действительность» (используется в случае методы с учителем ) термин «расстояния»: мы можем использовать методы v-кратный тест krzyowego Для диапазона чисел или покупки и наблюдения за удаленным наблюдением (в тестовом образце) из центров закупок (для k -rednich), в случае анализа, покупка EM- методов будет эквивалентна среднему логарифму надежности, рассчитанному для наблюдений из тестовых образцов.
Просмотр результатов v-перекрестной проверки. Результаты v-перекрестной проверки лучше всего просматривать на простом линейном графике.
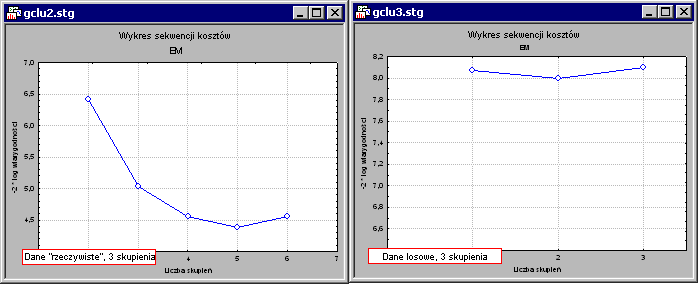
На иллюстрации показаны результаты анализа данных, который, как известно, содержит три наблюдения (известный файл данных Iris, представленный Фишером в 1936 году, широко обсуждаемый в литературе по анализ дискриминантной функции ). Мы также видим результаты анализа случайных чисел из нормального распределения на графике справа. «Реальные» данные (слева) характерны Дымовой участок (см. также Факторный анализ ) где функция стоимости (в данном случае это 2-кратная лог-достоверность данных перекрестной проверки при данных рейтингах параметров) сильно уменьшается с увеличением количества закупок, затем график становится почти полосатым (для более чем 3 покупок) и даже запускается расти, когда начинается przeuczenie , Случайные данные не имеют этого свойства, в этом случае вначале практически не происходит снижение функции стоимости, а затем она начинает быстро расти вместе с числами покупок (переоснащение).
Этот простой пример показывает, насколько полезным может быть метод v-перекрестной проверки при использовании его в методах k- mean и EM для определения «правильного» объема данных.

& copy Copyright StatSoft, Inc., 1984-2011
STATISTICA является торговой маркой StatSoft, Inc.
Похожие
Как написать бизнес-план для интернет-магазина?... анализ рынка, маркетинговая стратегия и анализ финансовой ликвидности в одном . Независимо от того, ищете ли вы инвестора или просто планируете открыть собственную электронную коммерцию - создайте ее в начале пути, и в будущем вы избежите многих проблем. Посмотрите, как написать бизнес-план для интернет-магазина. промедление Прежде чем мы перейдем к существу дела, я хотел бы немного поговорить о промедлении (в противном Светлое будущее рынка серебра. анализ
Серебро - это благородный металл, который в инвестиционной среде рассматривается как «безопасная гавань» и, подобно золоту, служит для обеспечения безопасности капитала в неопределенные времена. Однако, в отличие от золота, на промышленное использование которого приходится всего 10% мирового спроса на этот металл, промышленное использование серебра составляет более 55%. Серебро нашло широкое применение в электронике. Благодаря отличной электрической проводимости, это лучший выбор для Система бизнес-аналитики - инструмент для точного управления
Business Intelligence, или Business Intelligence, представляет собой очень широкую концепцию - ее сфера охвата охватывает такие области, как поиск сбережений, повышение эффективности производства, построение сценариев «что, если» или комплексный финансовый анализ. Вездесущий «сбор» информации представляет собой огромную проблему для аналитиков с одновременным отсутствием связи между системами и данными. В повседневной работе многие из нас по-прежнему используют два, три или более инструментов
Комментарии
Фокус установлен там, где и должен?Фокус установлен там, где и должен? Достаточна ли глубина резкости? Хотя мы можем сделать эти оценки визуально, цифровые камеры предлагают ряд инструментов, которые позволяют им быть быстрее и увереннее. Одной из таких функций является гистограмма фотографии . Предварительный просмотр зеркальной камеры Sony α550 предлагает удобное меню, в котором мы можем ее просмотреть. Гистограмма также может быть представлена во время съемки. Гистограмма представляет собой четкий график, Kantar Millward Brown по заказу Польского исследовательского агентства провел анализ «Что женщины читают о красоте?
Kantar Millward Brown по заказу Польского исследовательского агентства провел анализ «Что женщины читают о красоте?» - это подразумевает, среди прочего, что женщины, которые пользовались услугами SPA или салоном биологической регенерации в прошлом году, обычно достигают : «Twój Styl» - 25,2 процента, «Сокровище» - 10,8 процента, «Аванти» - 10 процентов, «Viva!» - 9,2 процента, «Гала» - 8,9 процента. Как отмечает Моника Крокевич из Бауэра, ежемесячно "Twój Styl" как один из первых журналов в Польше
Как, однако, будет определять расстояния между новыми кластерами, которые возникают из связанных объектов?
После обсуждения в предыдущем абзаце относительно групповых случаев или переменных, почему бы не спросить обе группы одновременно?
Фокус установлен там, где и должен?
Достаточна ли глубина резкости?
Kantar Millward Brown по заказу Польского исследовательского агентства провел анализ «Что женщины читают о красоте?